Solving Algorithmic Problems in The Wild
For most software engineers, algorithmic problems are this bizarre type of problems that they only have to know in order to succeed in their interviews and get a job. Perhaps most readers will concede that they are sometimes useful, but I would imagine only a handful few studied solving algorithms outside of LeetCode or their college classes.
The premise of this article is that the methods for solving your Algorithms homework or LeetCode mediums are ill-equipped to handle the algorithmic problems you will face as a software engineer, and I hope to provide you with a fresh technique I myself employ. To be fair to the reader, the two examples I talk about in the article are far from any reasonable definition of the Wild, but let’s bear with me for now!
What is the problem with solving LeetCode?
The problem is not that solving LeetCode problems is bad, per se, but how the platform is designed in getting you to solve questions.
- The set of inputs is fixed and limited. Our instincts urge us to submit the least good enough code that passes all the existing inputs without considering the problem in more depth.
- The feedback from the platform is imminent, the number of tests passing, leading to the fact that we tend to ignore any other forms of possible feedback in terms of correctness and performance.
You might have realized that the two points have nearly identical indications, we need to understand what the problem is asking and the algorithm we design in more detail than LeetCode forces or sets us to do.
Why? Because we don’t have such nice input-output examples in reality. The ones we have are called unit tests, which are impossible to write for any sufficiently complex algorithmic problem. Imagine you are implementing a new shortest path algorithm for graphs that has certain types of properties, how many graphs and input-output examples would you need to see to have a sufficiently solid belief on the correctness of your algorithm?
If unit tests are insufficient, what can we do then? Well, there is the classic computer science approach of picking a pen and paper, writing down the invariants of the algorithms and an inductive proof; or you could just find a friend doing a Ph.D. in formal verification to write your proofs for you. For the rest of this article, I’ll work on convincing you that coming up with some properties for your problem and writing random tests in the style of QuickCheck is a better option.
What the heck is a property?
A property is a weird thing. In tutorials for property-based testing, you usually see properties like this.
list.reverse().reverse() == list
// Reversing a list twice gives you the same list
list.append(x).len() == list.len() + 1
// Adding an item to a list increases its length by one
sorted(list.sort())
// Sorting a list means it's sorted.
I’m sure these seem like no brainers to you, what do you mean sorting a list means it’s sorted, what the hell was it gonna be?
The reality is different though. The
meaning
of the sorting function is that the output respects to some ordering
(sorted(list) == true)
. We have deeply embodied that meaning, so such examples are obvious, and might feel like a child’s toy. For algorithms, data structures, or code that is less studied, less familiar, it is possible that we never thought about the meaning of them.
What are other types of properties?(there are perhaps more formal/correct names for these, please notify me if so)
- Modeling Property: The property that the results of our function is the same as another function. Perhaps we are writing a blazingly fast sorting function, and we want the result to be the same as the result of bubble sort.
-
RoundTrip Property:
Roundtrip properties are usually found in programs such as parsers or encoders. One example I previously used is
JSON.parse(JSON.stringify(object)) === object. You can imagine we actually rely a lot on this property a lot while sending data over the wire. - Effect Properties: Effect properties build the expectation that the result of some computation is a (simple)function of the input. When we don’t care about the way a computation is performed, but rather the effect of the computation on some state/variable, we use effect properties. All 3 examples I gave in the beginning are effect properties.
Where does properties and algorithmic problems come together?
As I said, LeetCode is all nice and good, but in reality, we have to define the correctness of our programs. Property-based tests with well-crafted properties provide more confidence in such correctness than unit tests. In the rest of the article, I will provide two examples of properties I came up with for my own problems.
The first problem I will talk about is a familiar one, it’s actually a LeetCode medium in addition to being an elementary school problem,
pow(x, n)
.
The problem, as you might have guessed, asks us to write a function that will give us the n’th power of x.
A simple and intuitive solution might look like the one right below.
double result = 1;
for (int i = 0; i < n; i++) {
result *= x;
}
return result;
The problem here, for the careless reader, is that for
n < 0
, this code just returns 1. We can solve this problem by leveraging an algebraic identity,
x^-n = (1/x)^n
.
if (n < 0) {
x = 1 / x;
n = -n;
}
// x^-n = (1/x)^n
double result = 1;
for (int i = 0; i < n; i++) {
result *= x;
}
return result;
This code is indeed a bit slow. It is linear with n, meaning that it takes roughly n multiplications to get to the result. We can get better by using two more algebraic identities,
x^2n = (x^2)^n, x^2n+1 = x * x^2n
. As you might have realized, we just cut our work in half at each step, resulting in an exponential speed-up.
public double pow(double x, int n) {
if (n == 0) {
return 1;
}
if (n < 0) {
x = 1 / x;
n = -n;
}
if (n % 2 == 0) {
return pow(x * x, n / 2);
} else {
return x * pow(x * x, n / 2);
}
}
How do we make sure that our code is correct, though? The first option is to use a
Modeling Property.
We can just compare our results with
Math.pow
from the Java standart library.
pow(x, n) == Math.pow(x, n)
The second option is a less hacky one that actually relies on the meaning of the pow function.
pow(x, n) * x = pow(x, n + 1)
We can just generate many (x, n) pairs, run our pow function for
pow(x,n)
and
pow(x, n+1)
separately, and check the results.
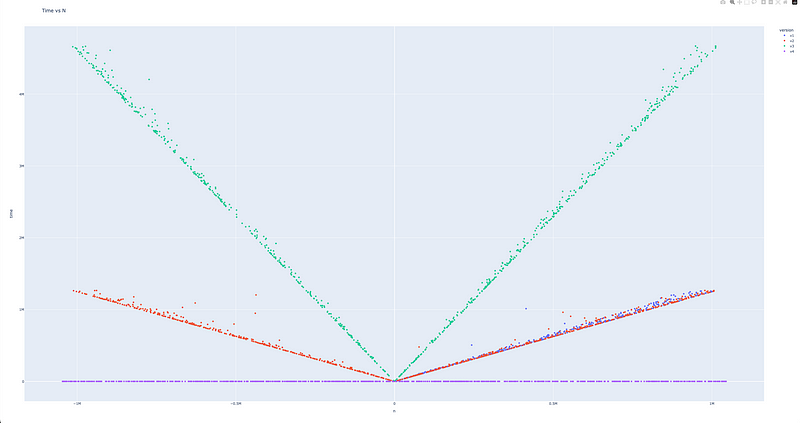
One nice feature of using Randomized Property-Based Testing is that it allows for benchmarking our code pretty easily. So, in addition to getting correctness, we get to measure performance. As the inputs are sampled from a large space, timing the results allows for comparing different algorithms easily. Below is the
Time vs N graph
obtained by running 4 versions of the
pow
function I implemented, measured over randomized inputs. The purple line that looks like it’s completely flat is the logarithmic implementation.
A More Realistic Example
I can hear you saying, come oon, who writes pow these days??? So I come bearing good news, I have a better example.
There is a board game called Quoridor that I started playing recently, and I decided to implement a mobile version of it to play with some friends overseas. Creating a mobile application has many hassles, but the first thing you need to do is to create a model of the game. The game has 81 squares, 144 tile locations, 10 1x2 tiles per player, and 2 pawns. There are several rules governing how tiles can be placed and how pawns can move, but one specific rule is pretty interesting. When placing tiles, opposing player must have at least one path toward their target open, you cannot shut them out.
This can be easily modeled as a Undirected Graph Reachability Problem . We can model the board as a 9x9 grid, where all adjacent squares have an undirected edge between them if there is no tile. If the pawn can reach any square in the first line of the opposing player after putting a new tile, then the move it valid. Below is a rough picture of the board, showing a path from the mid-top for the white pawn towards the left-bottom.
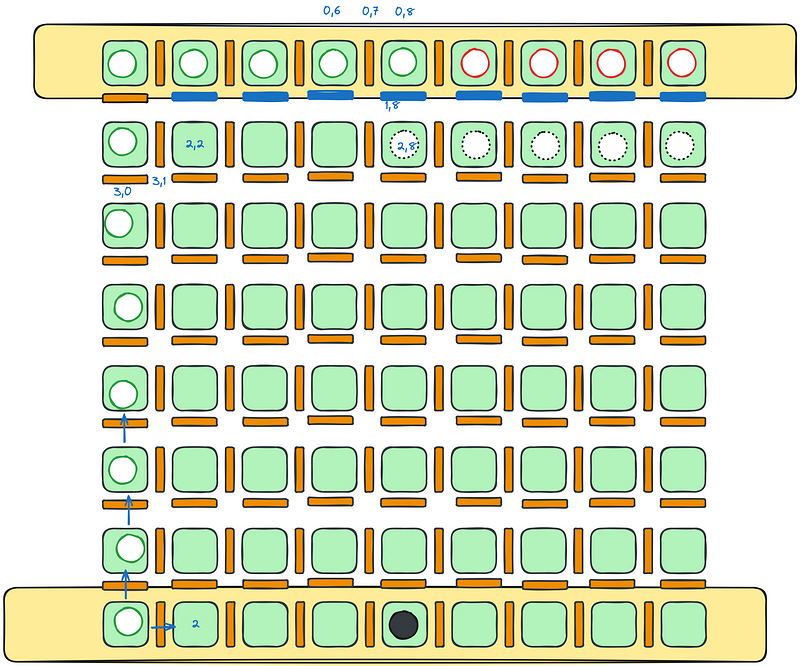
There are two ways of solving this problem. The first is constructing a graph out of the board and running an off the shelf reachability algorithm, the second is to implement a reachability algorithm on top of your own board, which is of course more fun(try to guess which one I decided to do).
After implementing a DFS(Depth First Search), I was met with the question of how to verify the correctness of my algorithm, how do I know I’m not too permissive or too restrictive?
I found two such properties.
- In the case of a permission, I ask for a witness(a path from the pawn to the target line). I follow through the line to make sure there are not tiles on the way.
- In the case of a restriction, things are more complicated. How can you guarantee there are no actual ways? I came up with an interesting solution to this one. I pick a point in the target line, I generate a random non-overlapping walk to the point, and I crush(remove) any tiles on the way, effectively generating at least one path. Running the algorithm again must give me a witness. This is of course a weak property, perhaps my random walks are not uncovering interesting paths that my code is not able to find. I am open to suggestions here!
I like this because (1) it was directly useful to me in a personal project, (2) it was a case where testing the algorithm was actually pretty hard by hand, (3) the property I came up with was fun to think of.
With this, I conclude my examples, and the article. As I said, I believe algorithms come up in many places around software projects, and they are hard to test and verify, especially if you’re not ready for it. I think Randomized Property Based Testing has a pretty good potential for both correctness and performance measurements, and it’s also really fun. If you like property based testing, you can check out my previous article.