Learner’s Guide to Property Based Testing#1

Property Based Random Testing is a flavor of testing that aims to use higher level specifications for testing instead of hand-writing or generating tests. It was first developed by Koen Claessen and John Hughes in 1999 as a software library for Haskell, called QuickCheck. There has been substantial development in the field since then, I will not bore you with lots of details as the purpose of this writing is to familiarize you with PBT(Property Based Testing).
To give a sense of what is happening, let’s first start by talking about Unit Tests.
A Unit Test is a test case aimed into testing a unit of a program, conventionally a function.
Above, you see a very simple test case for a function called $dummy\_sort$, which from the name and the structure it feels is supposed to sort a given function of possibly integers in ascending order.
But, this test case doesn’t actually give us very much knowledge on the function under test. It gives us a few clues we could perhaps generalize such as;
1- Function sorts the list [2, 1, 3, 4] correctly
2- (1) could imply that the function sorts all lists of length 4 correctly.
3- (1) also could imply that the function sorts all lists of integer permutations from 1 up to n.
4- (1) also could imply that the function sorts all lists of all lengths containing positive integers.
5- (1) also could imply this function sorts any type of list containing arbitrary integers in arbitrary length.
We might be expecting any one of the properties from (1–4), but a better possibility is that we are expecting 5. We could also expect properties 1–4, but the example also wouldn’t generalize to those, at least those other than property (1).
So ideally, we would need to create a set of examples that could represent the set of all cases we want our function to work on, so we need a way of defining this representative.
This is possible via creating what we will call properties in our code. Let me demonstrate with an example.
Function is_sorted checks if the list is monotonically increasing, meaning if no element is less than the element right before. As a logical statement, we can write is_sorted as
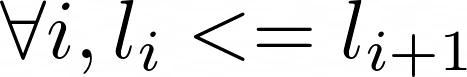
If you look carefully, you will see that this property that we wrote actually does not cover our needs. Suppose we have an implementation of dummy_sort as given below.
You will see that this means dummy_sort will always give a sorted list back to you, just not the one you would want.
So a better property could be writing the test as.
We just added a new check that looks if both lists have the same elements. Which would mean that if l contains an element that sorted_l does not contain, then our function does not do the right thing.
Yet, a careful reader will also realize the problem with this property. We can falsify it with the test case given below.
As one familiar with Python’s set data structure will see, a set will delete the duplicate elements in a list, hence this property will not be powerful enough too.
So this was our final property for testing. The resulting list must be sorted, and it should be a permutation of the initial list. If I did not do any mistakes in writing the is_permutation function, this function must be properly tested using this property.
There is another way of testing this, we could use a so-called Test Oracle for our property. Let’s say that we tested our dummy_sort extensively, and we used it in our software project for some time, we are quite sure that our function holds. And let’s assume we did not do Property Based Testing the first time, we were young and naive, we only did unit tests on the function, and we now want to use property based testing.
Now, we can use another notion of truth for our new sorting algorithm, whatever dummy_sort returns is our truth.
As our truth is defined using a previous implementation, we can use that implementation to test our new implementation. This is especially useful for testing optimizations and refactors in our code.
So what do we do, we now have a great testing infrastructure, we can just write a bunch of test cases without writing their results as given below.
It doesn’t seem great, right. We still have to write all of these tests, which is better than writing tests and the results, but still it feels like we could have something better.
Wait, we actually do! John Hughes and Koen Claessen has invented exactly that process.
Strictly speaking, what they invented is so much greater, fancier, and smarter than this, but it still relies on the same idea. A better version is given below.
So what’s better about this process is that
1- It remembers how many tests it has done, so it can be a bit stateful and remember the past in some sense. A simple example is we can generate lists based on logarithm of i, which would allow creating larger examples as we move forward with the tests, hoping that larger test cases might catch bugs smaller test cases could not demonstrate.
2- It “shrinks” the failing test case. Shrinking means finding a minimal example using a failed test case. Let’s say that our fancy sorting function has a bug, it crashes when the list has negative numbers. This bug is found with the following test case.
[11, 1,1,1,1,-1,1,2,442,34,2,4]But it could actually be found using.
[-1]If I had given you the first list as the failing case, it would take a lot of time to debug. There are lots of cases, maybe the function crashes with lists of size more than 10, or it cannot handle cases where 4 list elements are same.
But the second test case makes it very clear where the problem is and how to find and debug it.
Let me give you a very simple and not-so-smart generator and shrinker for the case given above.
This generation function generates random integers from the interval [-5, 10000) for a list of size log2size .
This shrinking function tries to shrink the list by truncating it from the beginning. At each step, a smaller list is created by excluding the first element; this allows creating minimal examples for debugging the actual problem.
This is the intuition behind Property Based Testing. There is a lot more to talk about, there is fuzzing, mutation based property based testing; there are clever ways of generating, shrinking, testing, writing properties… I want to write about those in the future too, I hope this was an interesting read for you.
For those interested, here are some more interesting reading to follow through.
- Original QuickCheck Paper ( https://www.cs.tufts.edu/~nr/cs257/archive/john-hughes/quick.pdf )
- A Description of Random PBT and Fuzzing explaining motivations behind it by Leo and Mike ( https://plum-umd.github.io/projects/random-testing.html )
- A (probably better than mine) medium post on PBT ( https://medium.com/criteo-engineering/introduction-to-property-based-testing-f5236229d237 )
- A talk by John Huges, “Dont Write Tests” ( https://www.youtube.com/watch?v=hXnS_Xjwk2Y )
Aside from the gists given above, I also uploaded the code to a single file for anyone interested as a convenience.
https://github.com/alpaylan/technical-blog-code/blob/main/pbt-1.py