Designing A Cryptic Language Puzzle
Last week, I published a Cryptic Language called Kelesce on my website, with a given text as the puzzle, and some set of clues I added to the website over the course of the week. Below is a small piece of the puzzle and a link to the website.
…
If you are interested in solving the puzzle, DO NOT READ the rest of this article, as it spoils the design and the solution. Click the link below and go to the puzzle site.
This article is two fold. The first part focuses my thought process on creating Kelesce, and the second part focuses on the decipher implementation.
A Very Short Cryptology Primer
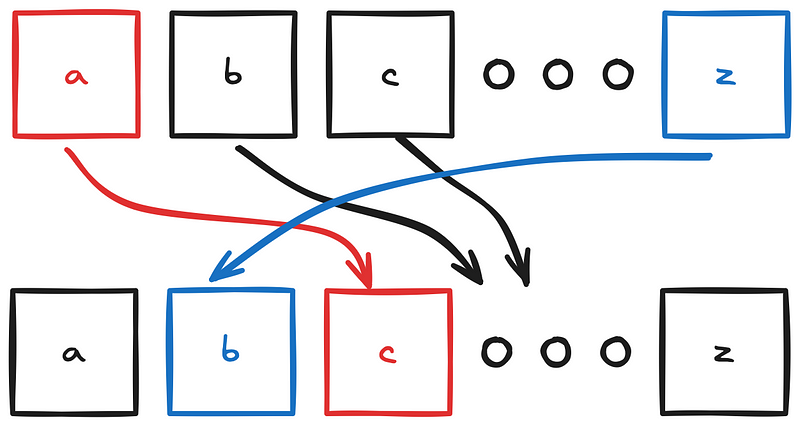
Cryptography 101 lectures usually start with the history of cryptology, and the famous Caesar Cipher . In a caesar cipher, encryption relies on some distance metric d that shifts the value of each letter by the given amount. Below, we see a Caesar(2), where each letter is mapped to the letter that comes 2 after them.
It is pretty simple to come up with a Caesar Cipher implementation on the fly. Below is a sample Python implementation for a very naive Caesar Cipher.
# This implementation assumes ASCII encoding,
# and all alphanumeric characters.
def caesar_cipher(text, shift):
result = ""
for i in range(len(text)):
char = text[i]
if char.isupper():
result += chr((ord(char) + shift - 65) % 26 + 65)
else:
result += chr((ord(char) + shift - 97) % 26 + 97)
return result
Deciphering a Caesar Cipher is also rather straightforward. You can just try all 25 potential shifts and see which one turns the cryptic result into a legible English sentence.
How to Design A New Cipher for Fun
So, we saw the oldest cipher in the world, now the question is can we design a new one that is not already out there. (full disclosure, I’m not a cryptography expert, and it’s very probably that my design is not actually novel)
There are several design principles I use:
- The cipher-text should be easy(and unambiguous) to decipher for someone who knows the ciphering mechanism.
- Cipher should consist of multiple layers, so the game(of solving) has a feeling of progress, and it is easy to provide hints when needed without spoiling all the fun.
- The layers should be not be simply rigorous mathematical obfuscations, using magic numbers that can only be discovered by some complex brute force search; but rather simple but interesting ideas.
I guess you could say these are kind of obvious, and not very helpful, so let’s try to get into the real thing. How to design Kelesce?
Phase 1: Decide on a central theme.
What should be the focus of the language? Should it be text, emojis, maybe music? I could use sound waves and frequencies, or I could go into 2d visual structures, which opens up a whole new world. I could use polygons, blobs made out of bezier curves, I could add new dimensions using colors, or as in the case of Kelesce, I could just use lines .
Phase 2: Decide on the unit of analysis.
Every cipher has a unit of
analysis, the smallest structure you can independently analyze. In the case of a Caesar
Cipher, the unit of analysis is one character. If instead we use a
Vigenère
cipher
, which generalized Caesar Cipher to arbitrary length units by using a list of
shifts instead of only one. Whereas a Caesar Cipher might have
2
as its shift factor, a Vigenère
cipher has some list [2, 5, 3, 6], where all characters
% 4
is ciphered with 2, all characters
%4 + 1
is ciphered with 5 and so on. The unit
of analysis for a Vigenère cipher is the length of its key list.
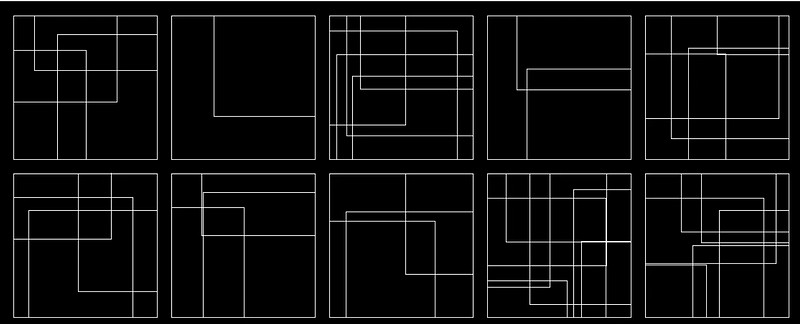
In our case, the unit of analysis is a word. Each square in Kelesce is a word, and the cipher-text for two different words do not depend on each other, hence they can be separately analyzed.
Phase 3: Start putting your obfuscation layers in.
Now that we decided on our theme and the largest dependent cipher unit, we need to decide how to cipher it. We need to define some signals and noise that will disguise our signals. The signals define how we map the cipher-text with the plain-text, and the noise hides the signals from the viewer.
Layer 1: Represent every letter using ratios.
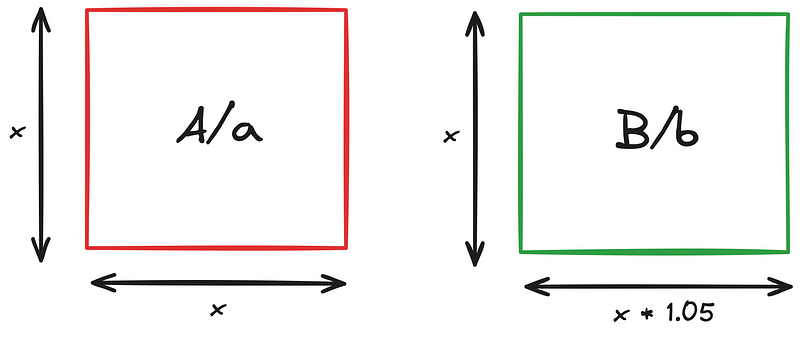
The first decision I made when creating Kelesce was about how to express each letter, and I decided to use ratios that increase/decrease by 0.05 throughout the English alphabet.
A/a => 1
B/b => 1.05
C/c => 0.95
D/d => 1.10
E/e => 0.90
... and so on
It is important to note that these ratios can be actually used in so many different ways. I could use them as line lengths with respect to some magic number, I could make them areas, or I could turn them into colors. There goes my second decision.
Layer 2: Represent each letter using 2 lines.
I decided to use 2 lines for each letter, where the ratio is the length of the first line to the length of the second line.
This decision has an important consequence, namely that it reduces the scope of the cipher to mostly programmers, as it’s quite hard to manually measure the ratios.
So, now we know how to decode a letter when we see one, we just compute the ratios of the lines and we are done, but where do we even put the lines?
Layer 3: Rotate, rotate, rotate, rotate…
We defined how to represent a word in abstract terms, but how do we concretely place and compose the letters such that they are unambiguously decipherable?
The first decision I made is to put them inside squares.
The second decision is that each line pair starts from a random position on one side of the square, and makes a counter-clockwise turn(top-to-right, right-to-bottom…).
The third decision is that the first line starts from the top, and runs clockwise(top, right, bottom, left, top…).
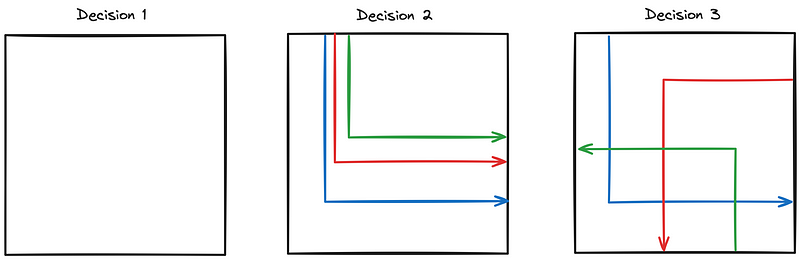
The next question is how to handle the fifth letter, because now we have ambiguity. If there are two lines starting at the top, which one is the first and which one is the fifth?
Layer 5: When in doubt, nest.
This was an choice, when you need to reuse a side, pick a position on the inner rectangle constrained by the previous word. See the figure below for clarity.
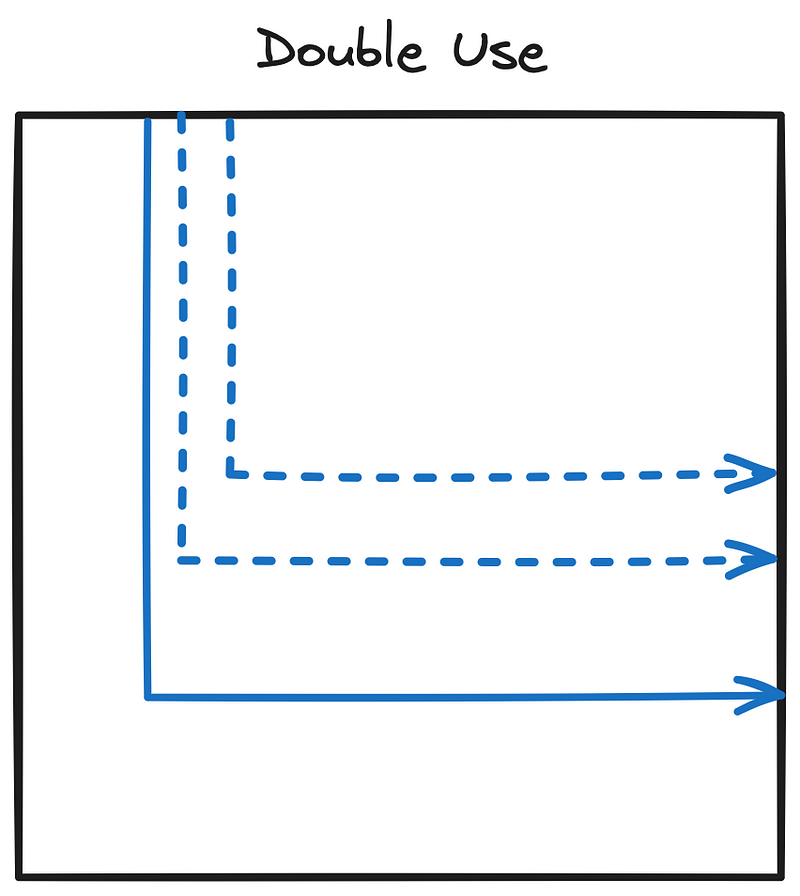
This way, when you are reading the cipher-text, you start from the largest rectangle for the current edge of the rectangle, and go progressively inside, as if you’re peeling an onion.
Layer 6: Normalization
As you might have realized, I never talked about punctuations, and I use the same ratios for uppercase and lowercase letters, so the given plain text is first processed into a normalized form, and then converted into the lines and squares.
The first part of the normalization is that all characters that are not from the English alphabet are deleted, all characters are lowercased, and words are merged together.
"Hello, World!" => "helloworld"
With that, we conclude our obfuscation layers. There is one more small transformation I added for the sake of aesthetics, but it doesn’t affect the cipher that much. I wanted the puzzle to look nicer, so I added a little bit of padding words at the end. If the length of the text is not a multiple of 5, then a number of “hahaha” is added to the text to make it a multiple of 5. So, the last word in the clue is hahaha .
Part 2: How to implement a deciphering algorithm for Kelesce?
I hope others who solve the puzzle on their own post some write-ups, but for now I’ll share my own methodology.
The 4th clue, which is “Two is all you need”, actually refers to the solution, where 2 pixels are actually all you need. If you can detect the starting and end points of a line, you can decide which letter it is.
The algorithm for line detection is rather cumbersome to implement but it’s not really complicated.
The first step is to find all points where a line is perpendicular to an edge.
The second step is to follow the line as far as it goes.
The third step is to turn counter-clockwise, and find the other edge.
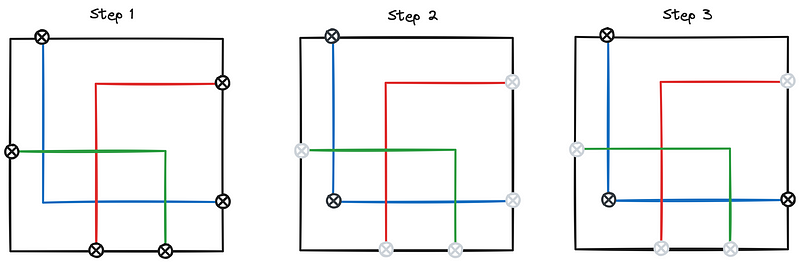
The forth step is to convert the line ratios into letters, and order the letters in the way they are positioned, and we are done.
Of course, this algorithm has a few pitfalls(if a parallel line is right next to the edge, it might think there are 198 lines leaning against that edge, or if there are two overlapping lines), but they don’t show up in practice.
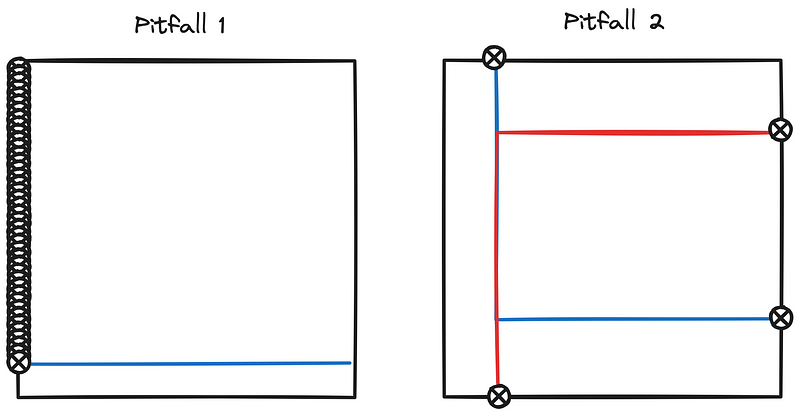
Close-up
With that, I conclude the article. If you tried to solve the puzzle, I hope you had fun trying! If you just read the article, I hope you liked it!